
فهرست مطالب
مقدمه
روش های حل متفاوتی برای حل انواع مسائلی که در ادبیات این حوزه ارائه شده است، وجود دارد. برخی از این روش ها به دنبال یافتن حلی مناسب برای مسئله می باشند که شرایط خاصی را که تصمیم گیرنده تعیین می کند ارضا کند، نوع دیگر از روش های حل به دنبال یافتن جواب بهینه سراسری (Global Optimum) و یا بهینه موضعی (Local Optimum) برای تابع هدف می باشند. در این مقاله انواع این روش های حل در سه قالب زیر مورد بررسی قرار خواهند گرفت:
- روش های حل دقیق
- روش های حل ابتکاری
- روش های حل فراابتکاری
روش های حل دقیق مسئله چیدمان تسهیلات
از جمله مهمترین روش های دقیق ارائه شده در ادبیات روش انشعاب و تحدید می باشد. این روش برای حل مسئله QAP استفاده شده است. علت این موضوع استفاده از متغیرهای صفر و یک در مدل QAP می باشد. اما در ادبیات تنها مسائلی با اندازه کوچکتر از ۱۶ توسط این روش دقیق حل شده است. اما علی رغم بهینه بودن این روش کامپیوترهای پیشرفته هم قادر به حل مسائل بزرگتر نمی باشند.
از میان روش های دقیق ارائه شده در ادبیات می توان به روش ارائه شده توسط Kouvelis و Kim در سال ۱۹۹۲ اشاره کرد که الگوریتم انشعاب و تحدید را برای حل یک مسئله حلقه ای، که دارای یک جهت است استفاده کرد (Kouvelis&Chiang1992). همچنینMeller و همکارانش در سال ۱۹۹۹ از همین روش برای حل مسئله چیدمان n تسهیل مستطیلی شکل در n مکان مستطیلی استفاده نموده اند. Kim و Kim در سال ۱۹۹۹ مسئله پیدا کردن نقاط (P/D) با تسهیلات یک اندازه و در یک چیدمان داده شده را معرفی کردند. تابع هدف مسئله به صورت کمینه کردن مسافت طی شده بین نقاط (P/D) تعریف شد. نویسندگان یک الگوریتم انشعاب و تحدید برای حل این مسئله پیشنهاد دادند. Rosenblatt در سال ۱۹۸۶ از برنامه ریزی پویا برای حل چیدمان پویای تسهیلات که در آن تمام تسهیلات دارای اندازه یکسان می باشند استفاده کرد. این روش تنها قابلیت حل مسائل کوچک را داشت (۶ تسهیل و ۵ دوره زمانی).
در سال های قبل از دهه ۶۰ میلادی تعداد قابل ملاحظه ای از گزارش علمی در ارتباط با توسعه روش های حل بهینه مسئله QAP انجام شد. از این میان بیشتر پژوهشگران بر روی گسترش دو روش زیر تحقیق کردند:
- الگوریتم انشعاب و تحدید
- الگوریتم صفحات برش
الگوریتم انشعاب و تحدید
اولین کسانی که الگوریتم انشعاب و تحدید را توسعه دادندGilmore در سال ۱۹۶۲ و Lawler در سال ۱۹۶۳بودند. تفاوت عمده بین دو کار مستقل از هم که توسط این دو نویسنده انجام شد، چگونگی محاسبه حد پایین بود. هر دو الگوریتم بدون هیچ شرطی جواب های بالقوه را ارزیابی می کردند. در این دو روش اگر هیچ قانونی برای هرس کردن درخت تصمیم در نظر گرفته نشود، آنگاه ممکن است فرآیند این دو روش ما را به یک تکنیک محاسباتی ناکارآمد راهنمایی کنند (Kusiak&Heragu,1987).
بجز دو الگوریتم فوق دو الگوریتم دیگر توسط Land در سال ۱۹۶۳ وGavett و Plyter در سال ۱۹۶۶ توسعه داده شد. این الگوریتم ها یک جفت از تسهیلات را به یک جفت از مکان ها تخصیص می دهد. در حالی که الگوریتم ارائه شده توسطGilmore در سال ۱۹۶۲و Lawler در سال ۱۹۶۳ یک تسهیل را به یک مکان تخصیص می دهد. الگوریتم های فوق الذکر با استفاده از یک فرآیند مرحله به مرحله تسهیلات را به مکان ها تخصیص می دهد. تمامی الگوریتم های بهینه نیازمند حافظه محاسباتی زیادی هستند (Burkard,1984).
Lavalle و Roucairolدر سال ۱۹۸۵ برای حل مسئله QAP استفاده از یک الگوریتم انشعاب و تحدید موازی را پیشنهاد دادند (Lavalle&Roucairol,1985). این الگوریتم به طور موازی از چندین محل در درخت تصمیم شروع به جستجوی جواب بهینه می کند. تا به حال نتایج محاسباتی گزارش شده نشان می دهد که الگوریتم انشعاب و تحدید موازی برای حل مسائل مکانیابی تسهیلات با دوازده تسهیل یا بیشتر نیاز به حافظه محاسباتی زیادی دارد (Lavalle&Roucairol,1985).
Burkard در سال ۱۹۷۳یک الگوریتم حل بهینه برای مسئله QAP پیشنهاد داد (Burkard,1984) الگوریتم او براساس الگوریتم کاهش در یک ماتریس مربعی بنا شده بود. در سال ۱۹۷۵،Bazaraa یک الگوریتم انشعاب و تحدید برای حل مسئله چیدمان تسهیلات ارائه داد که در هر حل میانی یک چیدمان P تسهیله متناظر با آن حل ارائه می دهد (Bazaral,1975). Bazaraa و Elshafei در سال ۱۹۷۹ یک الگوریتم انشعاب و تحدید را برای حل مسئله QAP پیشنهاد دادند .(Bazara&Kirca,1979) این الگوریتم با استفاده از یک فرآیند مرحله به مرحله یک تسهیل را به مکانی اشغال نشده تخصیص می داد. Kaku و Thompson در سال ۱۹۸۶یک الگوریتم انشعاب وتحدید را ارائه دادند که از الگوریتم ارائه شده توسط Lawler در سال ۱۹۶۳به خصوص برای مسائل بزرگ کاراتر بود (Kaku&Thompson,1986).
الگوریتم صفحات برش
Bazaraa و Sherali در سال ۱۹۸۰ الگوریتم صفحه برش ارائه دادند.Burkard و Bonninger در سال ۱۹۸۳ یک الگوریتم صفحه برش برای حل مسئله QAP ارائه دادند (Burkard&Bonninger,1983).
الگوریتم های انشعاب و تحدید و صفحات برش دارای پیچیدگی زمانی زیادی هستند. به عنوان مثال بزرگترین مسئله چیدمانی که با استفاده از الگوریتم صفحات برش حل شده است دارای هشت تسهیل بوده است. تجربیات استفاده از الگوریتم انشعاب و تحدید نشان داده است که این الگوریتم در مراحل اولیه انشعاب به جواب بهینه دست می یابد ولی این جواب تا هنگامی که تعداد زیادی از جواب ها تک تک شمرده نشود تایید نمی شود (Bazara&Kircar,1979)، (Burkard&Bouninger,1983). این مسئله موجب شد که تعدادی از تحقیقات بر روی توسعه روش هایی بدون تایید بهینگی انجام شود. این تحقیقات موجب توسعه روش های هیورستیک انشعاب وتحدید شد. Burkard در سال ۱۹۸۴ دو شرط اساسی را برای توقف الگوریتم انشعاب و تحدید ذکر کرد (Burkard,1984):
- شرط توقف براساس محدودیت زمانی؛ بدین صورت که فرآیند محاسباتی پس از گذشت زمان از پیش تعیین شده متوقف می شود.
- شرط توقف براساس کیفیت حد بالای جواب؛ بدین صورت که پس از گذشت یک بازه زمانی از پیش تعیین شده که جواب بهبودی نداشت حدبالای مسئله درصدی کاهش می یابد.
الگوریتم های حل ابتکاری مسئله چیدمان تسهیلات
الگوریتم ها و روش های هیورستیک بخش عمده ای از ادبیات حوزه چیدمان تسهیلات را به خود اختصاص می دهد. الگوریتم های هیورستیک را می توان به دو گروه عمده سازنده و بهبود دهنده تقسیم کرد (Singh&Sharma,2006) الگوریتم های سازنده از ساده ترین و قدیمی ترین الگوریتم هایی هستند که از لحاظ مفهومی و عملی برای حل مسائل FLP مورد استفاده قرار گرفته اند، اما کیفیت جواب آن ها چندان رضایت بخش نیست. الگوریتم های بهبود دهنده با استفاده از یک جواب شدنی اولیه و تعویض تخصیص ها، سعی در بهبود جواب اولیه دارند (Singh&Sharma,2006). الگوریتم های بهبود دهنده به سادگی با الگوریتم های سازنده قابل ترکیب هستند. الگوریتم CRAFT از جمله رایج ترین الگوریتم های بهبود دهنده می باشد که براساس تعویض دودویی عمل می کند (Armour,1963). در اکثر موارد به دلیل محاسبات زیاد این الگوریتم ها، نرم افزارهایی برای آن ها تهیه شده است. لیستی از این نرم افزارها در جدول زیر آورده شده است.
| ردیف | نام بسته ارائه شده | ارائه دهنده |
|---|---|---|
| 1 | CRAFT | Dr. Gordan Armour |
| 2 | ALDEP | Seehof and Evans |
| 3 | CORELAP | Dr. Moore James |
| 4 | PLANET | Michael P. Deisenroth |
| 5 | COMP2 | Teichholz Eric |
| 6 | COMPROPLAN COMSBUL | Kaiman Lee |
| 7 | CORELAP8 | Robert C. Lee |
| 8 | DOMINO | Robert Dhillon |
| 9 | GRASP | Teichholz Eric |
| 10 | IMAGE | Dr. Johnson T.E. |
| 11 | KONUVER | Dr. Warnecke |
| 12 | LAYADAPT | Dr. Warnecke |
| 13 | LAYOPT | Raimo Matto |
| 14 | LAYOUT | John S. Gero |
| 15 | LOVE | Dr. Love R.F. |
| 16 | MUSTLAP2 | Dr. Warnecke |
| 17 | OFFICE | Dr. Vollman Thomas |
| 18 | PLAN | McRoberts K. |
| 19 | PREP | Anderson David |
| 20 | RG and RR | Moucka Jan |
| 21 | RITZMAN | Dr. Ritzman L.P. |
| 22 | SISTLAPM | Dr. Warnecke |
| 23 | SUMI | Prof. Spillers |
| 24 | Terminal Sampling Procedure | Hitchings G. |
| 25 | SPACECRAFT | Johnson |
| 26 | COFAD | Tompkins and Reed |
| 27 | SHAPE | Hassan, Hogg and Smith |
| 28 | QLAARP | Banerjee et al. |
| 29 | LOGIC | Tam |
| 30 | MULTIPLE | Bozer, Meller, and Erlebacher |
| 31 | FLEX-BAY | Tate and Smith |
| 32 | DA (Adjacency Based) | Foulds and Robinson |
| 33 | MATCH (Adjacency Based) | Montreuil, Ratliff and Goetschalckx |
| 34 | SPIRAL (Adjacency Based) | Goetschalckx |
| 35 | FACOPT | Balkrishnan et al. |
این الگوریتم ها عموما براساس درجه نزدیکی و یا مسافت کار می کنند (Armour,1963). به عنوان مثال الگوریتم MATCH توسط Montreuil و همکارانش در سال ۱۹۸۷ و الگوریتم SPIRAL توسط Goetschalckx در سال ۱۹۹۲، بر اساس درجه نزدیکی عمل می کنند. الگوریتم CRAFT در سال ۱۹۸۷ توسط Montreuil و همکارانش، الگوریتم SHAPE توسط Hassan و همکارانش در سال ۱۹۸۶، الگوریتم LOGIC توسط Tam در سال ۱۹۹۲، الگوریتم MULTIPLE توسطLee و همکارانش در سال ۲۰۰۵ و الگوریتم FLEX-BAY توسط Tate و Smith در سال ۱۹۹۵ براساس مسافت عمل می کنند.
تفاوت عمده این دو نوع از الگوریتم ها در تابع هدف آن ها می باشد. تابع هدف برای الگوریتم هایی که براساس درجه نزدیکی عمل می کنند عموما به صورت معادله زیر می باشد. که در آن پارامترها به صورت زیر تعریف می شود.
![]()
- xij برابر با یک خواهد بود اگر i مجاور دپارتمان j باشد و در غیر این صورت برابر با صفر می باشد
- rij درجه نزدیکی دو دپارتمان i و j
روش های حل فراابتکاری مسئله چیدمان تسهیلات
اصولا روش های دقیقی که بتوانند به صورت ریاضی جواب بهینه را به دست آورند، وجود نداشته و یا در صورت وجود قابلت کاربرد عملی ندارند و اصطلاحا به کارگیری آن ها خیلی گران است. لذا بایستی روش هایی را جستجو کرد که حداقل بتوانند جواب های خوب (که ممکن است دیگر بهینه نباشند) را ارائه دهند. این گونه روش ها را روش های متاهیورستیک می نامند. روش های متاهیورستیک روش هایی هستند که با استفاده از شیوه های ابتکاری که غالبا ایده اصلی آن ها از مسائل دنیای واقعی الهام گرفته شده است، سعی در پیدا کردن جوابی نزدیک به بهینه دارند. تعداد زیادی از این الگوریتم ها در ادبیات معرفی شده اند که ما به بررسی مهمترین و پرکاربردترین آن ها در حل مسائل چیدمان می پردازیم. مهمترین و پرکاربردترین این الگوریتم ها عبارتند از:
- الگوریتم مورچگان یا Ant Colony
- الگوریتم ژنتیک یا Genetic Algorithm
- الگوریتم بازپخت شبیه سازی شده یا Simulated Annealing
- الگوریتم جستجوی ممنوع یا Tabu Search
الگوریتم مورچگان
الگوریتم مورچگان از رفتار طبیعی کلونی مورچگان الهام گرفته شده است. اساس این الگوریتم از رفتار طبیعی مورچگان برای یافتن غذا گرفته شده است. در کلونی مورچگان هر مورچه یک ماده به نام فرمون (Pheromone) در مسیر حرکت خود از آشیانه به سوی غذا و بالعکس برجای می گذارد. دیگر مورچگان فرمون را بو می کنند تا منبع غذا را پیدا کنند. فرمون بیشتر در یک مسیر، احتمال انتخاب آن مسیر را بیشتر می کند (Solimanpur et al.,2005). بنابراین پس از گذشت مدتی تمام مورچگان از کوتاهترین راه بین لانه تا منبع غذا استفاده می کنند. برای اطلاعات بیشتر به مقاله نوشته شده توسط Dorigo و همکارانش در سال ۱۹۹۶ مراجعه کنید (Dorigo et al.,1996). در الگوریتم AA هر مورچه به عنوان یک عامل محاسبه در نظر گرفته می شود. الگوریتم AA از چندین عامل محاسبه تشکیل شده است تا مکانیزم جستجو را برای جستجوی فضای جواب راهنمایی کند تا جواب بهینه به دست آید (Solimanpur et al.,2005). لازم به ذکر است که عامل محاسباتی لزوما مانند یک مورچه واقعی عمل نمی کنند. بنابراین بعضی از مطالب نقل شده در آینده ممکن است کاملا با زندگی واقعی مورچگان همخوانی نداشته باشد. به طور مثال مورچه های مصنوعی می توانند مسیر حرکت خود را به خطر بسپارند. همچنین آن ها شامل اطلاعاتی از روش هیورستیک مورد استفاده می باشند. این مورچگان مصنوعی پس از هر تکرار دور ریخته می شوند (Solimanpur et al.,2005). در یک الگوریتم AA باید عناصر ذیل را مشخص کرد:
- ساختار جواب
- اطلاعات هیورستیک
- قانون بروز رسانی فرمون
- احتمال انتخاب
- الگوریتم جستجوی محلی
- شرایط توقف
شیوه های مختلف به کارگیری این الگوریتم، می تواند انواع مختلفی از الگوریتم AA را نتیجه دهد. الگوریتم AA اخیرا به طور گسترده ای برای حل مسائل بهینه سازی ترکیبی استفاده شده است. به خصوص الگوریتم AA به طور موثری توانسته است برای حل مسائل FLP که به صورت QAP مدل سازی شده است به کارگرفته شود. در سال ۱۹۹۹StMutzle وDorigo کاربردهای مختلف الگوریتم AA را برای حل مسئله QAP مرور کرده اند (StMutzle&Dorigo,1999). در سال ۱۹۹۷ Taillard وGambardella یک الگوریتم AA سریع برای حل مسائل چیدمان با استفاده از فرموله کردن QAP ارائه داده اند که در هر تکرار الگوریتم فقط از یک مورچه استفاده می شود(Taillard&Gambardella,1997). در سال ۱۹۹۹ Gambardella و همکارانش یک الگوریتم ترکیبی به نام HAS-QAP برای حل مسائل QAP ارائه دادند (Gambardella et al.,1997). ایده اصلی این روش این بود که از فرمون باقی مانده برای ایجاد یک جواب استفاده نمی کرد بلکه برای تغییر جواب استفاده می کرد.
در سال ۲۰۰۰ StMutzle و Hoos یک الگوریتم Max-Min AA به نام MMAS برای حل QAP پیشنهاد کرد که در آن تنها مورچه اجازه داشت از خود فرمون برجای بگذارد، در این الگوریتم از یک حد برایTrail Level استفاده شد تا از ایستایی جلوگیری شود (StMutzle&Hoos,2000). در سال ۲۰۰۵،Solimanpur و همکارانش بیان داشتند که یک فرض اساسی که در مدل QAP وجود دارد این است که مکان های کاندید مشخص هستند. بنابراین فاصله بین محل از قبل به صورت یک مقدار عددی معلوم است (Solimanpur et al.,2005). آن ها در مقاله خود بیان داشتند که فاصله بین دو ماشین متفاوت است. بنابراین فرض فاصله بین توالی مرتبط با FLP یکسان نمی باشد و بنابراین هیچ یک از الگوریتم های AA ارائه شده قادر به حل این مسئله نمی باشند. باید این نکته را در نظر داشت که این مسئله بسیار مشکل تر از QAP می باشد (Meller et al., 1999). در کار انجام داده شده توسطSolimanpur و همکارانش در سال ۲۰۰۵ دو فرض اساسی در نظر گرفته شده بود:
۱- ماشین ها مستطیلی می باشند و با ابعاد متفاوت و فاصله بین آن ها به صورت مرکز به مرکز محاسبه می شود.
۲- فاصله بین هر دو ماشین متغیر است.
این فرض یک فرض مهم در مسائل سیستم های تولیدی در دنیای واقعی می باشد. هیچ شکی در میان نیست که نرخ تولید ماشین های مختلف در یک سیستم واقعی متفاوت است و این فرض نتیجه می دهد که فضای لازم جهت انبارش قطعات نیمه ساخته در جریان فرآیند ساخت یکسان نیست. برخی از فاکتورهای موثر در این فاصله به شرح زیر می باشند (Solimanpur et al.,2005).
- مسیر و مقدار تولید.
- زمان لازم برای انجام پروسه تولید توسط هر ماشین.
- شکل و اندزه قطعات.
- نوع MHD.
- نوع و سایز پالت های استفاده شده.
الگوریتم AA می تواند مانند یک مدل صف یا شبیه سازی برای یافتن فضای مورد نیاز میان ماشین ها به کار رود (Solimanpur et al.,2005).
ایده اصلی که این تابع هدف بر اساس آن تعریف شده است این است که اگر دو دپارتمانی که دارای درجه نزدیکی زیادی هستند کنار یکدیگر قرار بگیرند هزینه حمل و نقل مواد کاهش می یابد. تابع هدف الگوریتم هایی که براساس مسافت عمل می کنند عموما به صورت معادله زیر می باشد.
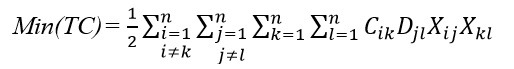
فلسفه این تابع هدف این است که افزایش مسافت طی شده هزینه کل را افزایش می دهد. در این معادله اگر Cik را با Fik به صورت معادله زیر جایگزین کنیم تابع هدف به دست آمده مربوط به چیدمان چندطبقه ای می باشد (Solimanpur et al.,2005).
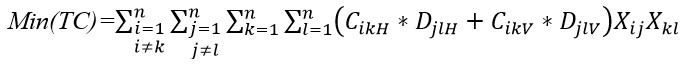
در جایی که CijH و DjiH به ترتیب نشاندهنده هزینه حمل ونقل و فاصله افقی می باشند و CijV و DjiV به ترتیب نشان دهنده هزینه حمل و نقل و فاصله عمودی می باشند.
الگوریتم ژنتیک
الگوریتم GA یک روش جستجوی موثر در فضاهای بسیار وسیع و بزرگ است که در نهایت منجر به جهت گیری به سمت پیدا کردن یک جواب بهینه می گردد که شاید نتوان در مدت زمان زندگی یک فرد به آن جواب بهینه دست یافت. دراین الگوریتم ها باید فضای جواب مسئله به فضای ژنتیک تبدیل شود بنابراین مزیت کار با الگوریتم های کد شده در این است که اصولا کدها قابلیت تبدیل فضای پیوسته به فضای گسسته را دارند. یکی از تفاوت های اصلی روش GA با روش های قدیمی بهینه سازی در این است که در GA با جمعیت یا مجموعه ای از نقاط در یک لحظه خاص کار می کنیم. نکته جالب دیگر این که اصول GA بر تعداد پردازش تصادفی یا به تعبیر صحیح تر پردازش تصادفی هدایت شده استوار است. بنابراین عملگرهای تصادفی فضای جستجو را به صورت انطباقی مورد بررسی قرار می دهند. در استفاده از الگوریتم سه تعریف اساسی زیر باید به طور مناسب انجام شود:
۱- تعریف تابع هدف یا تابع هزینه
۲- تعریف و پیاده سازی فضای ژنتیک
۳- تعریف و پیاده سازی عملگرهای GA
اگر سه قسمت فوق به درستی تعریف شوند، بدون شک GA به خوبی عمل خواهد کرد و در نهایت می توان با اعمال تغیراتی کارایی سسیستم را افزایش داد. الگوریتم GA با یک مجموعه آغازین از جواب های احتمالی از مسئله مورد نظر شروع می کند. این جواب های اولیه به عنوان جمعیت شناخته می شوند. مشخصه متمایز کننده هر فرد در جامعه کروموزن نامیده می شود. میزان ارزش هر کروموزن به وسیله تابع هدف و یا تابع برازندگی ارزیابی می شود. به طور مثال برای یک مسئله چیدمان تسهیلات هزینه حمل و نقل می تواند به عنوان یک تابع برازندگی معرفی شود (El-Baz, 2004). کروموزن هایی که در تکرار بعدی استفاده می شوند به وسیله تولید مثل ایجاد می شوند. در طی هر تولید مثل با استفاده از تغییر و یا ترکیب کروموزن ها جمعیتی جدید ایجاد می شود. ترکیب کروموزن ها (ادغام و تغییر کروموزن ها) یا به اصطلاح جهش نامگذاری شده اند (El-Baz, 2004). در نتیجه ادغام کروموزن ها با یکدیگر طی یک ر وش احتمالی ادغام شده و یک جفت کروموزن جدید ایجاد می کنند. در عمل ادغام جزئی از کروموزن تغییر کرده و کروموزنی جدید ایجاد می شود.
انتخاب کروموزن ها از جمعیت برای انجام ادغام و جهش با استفاده از ارزیابی آن ها به وسیله تابع برازندگی انجام می شود. هنگامی که جمعیتی جدید ایجاد می شود جمعیت قبلی حذف شده تا فضا برای جمعیت جدید محیا شود. این عمل در طی تکرارهای بعدی ادامه می یابد تا شرایط توقف ارضا شود. قدم های الگوریتم ژنتیک را بر اساس مسائل مختلف می توان به صورت متفاوتی تعریف کرد. اما علی رغم برخی تفاوت ها در کلیات الگوریتم های استفاده شده برای حل مسائل چیدمان تشابهات بسیاری وجود دارد. به عنوان نمونه قدم های GA را که در مقالات مورد استفاده قرار گرفته است می توان به صورت زیر بیان کرد (Mak,1998)
قدم ۱: ایجاد یک جمعیت اولیه از کروموزون ها با اندازه P و به صورت تصادفی
قدم ۲: کشف رمز هر کروموزن و ارزیابی مقدار تابع هدف هر کروموزن با حل کاندید متناظر با آن.
قدم ۳: به دست آوردن مقدار برازندگی هر کروموزن با استفاده از مقدار به دست آمده برای تابع هدف در قدم قبلی.
قدم ۴: با توجه به پارامترهای تعریف شده در مسئله، n تا از بدترین کروموزن ها را حذف کرده و با استفاده از کروموزن های باقی مانده جمعیت کنونی را تکمیل کنید.
قدم ۵: قانون انتخاب را به کار گیرید تا P عدد از کروموزن ها را به عنوان والد جهت تولید جمعیت جدید انتخاب کنید.
قدم ۶: یک جفت والد از کروموزن های انتخاب شده در قدم ۵ انتخاب کنید و با استفاده از عملگرهای ادغام و جهش یک فرزند جدید تولید کنید.
قدم ۷: فرزندان تولید شده در قدم ۶ را به جمعیت اضافه کنید. اگر تعداد جمعیت جدید به حد از پیش تعیین شده نرسیده است به قدم ۶ برگردید.
قدم ۸: شرایط توقف را بررسی کنید. اگر شرایط توقف به دست آمده است، جستجو را متوقف کرده و بهترین کروموزن تمام الگوریتم را به عنوان جواب نهایی در نظر بگیرید. کروموزن را رمزگشایی کنید. جواب متناظر جواب بهینه خواهد بود. در غیر این صورت یک جمعیت جدید تولید کنید.
الگوریتم بازپخت شبیه سازی شده
این الگوریتم یک شیوه تصادفی برای حل مسائل بهینه سازی پیچیده می باشد که ایده اصلی آن از فرآیند بازپخت جامدات گرفته شده است. این روش برپایه شبیه سازی مونت کارلو (Mont Carlo) می باشد که به شما اجازه می دهد مسائل بهینه سازی ترکیبی پیچیده را حل کنید (Azadivar&Wang,2000) نام آن ناشی از شباهت این روش با رفتار سیستم فیزیکی ذوب شدن یک ماده و کم شدن درجه حرارت آن به صورت تدریجی تا رسیدن به نقطه انجماد می باشد (Azadivar&Wang,2000) در این فرآیند ماده جامد حرارت داده می شود تا ذوب شود و سپس دمای ماده جامد بر اساس یک برنامه انجماد به آرامی کاهش می یابد تا اینکه ماده جامد به کمترین سطح انرژی یا سطح پایه دست یابد (Dorigo et al.,1996). اگر دمای اولیه به قدر کافی زیاد نباشد یا سرد شدن به سرعت انجام شود ماده جامد در حالت پایه ترک ها و یا عیب های زیادی خواهد داشت. McKendall و Shang Jin در مقاله خود در سال ۲۰۰۶ بیان می دارند که Kirkpatrick و همکارانش در سال ۱۹۸۳ جز اولین افرادی بودند که از SA برای حل مسائل بهینه سازی پیچیده استفاده کردند (McKendall&Shang ,2006).
قبل از توسعه روش های متاهیورستیک مانند GA ,TS ,SA روش های جستجوی محلی زیادی مانندAdd/Drop و Exchange Heuristics برای حل مسائل بهینه سازی پیچیده استفاده می شد. این روش های هیورستیک به طور ویژه ای با یک حل ابتدایی شروع می کنند و به طور احتمالی به سمت یک جواب همسایه حرکت می کند (یک جواب کمی بهتر از جواب اولیه) هزینه جواب همسایه به دست می آید و با هزینه جواب ابتدایی مقایسه می شود. اگر هزینه جواب همسایه بهتر باشد (کمتر از هزینه جواب ابتدایی) این جواب به عنوان بهترین جواب انتخاب می شود و به عنوان جواب ابتدایی در تکرار بعدی استفاده می شود. در غیر این صورت جواب آغازین به عنوان جواب ابتدایی تکرار بعدی استفاده می شود. این رویه تا هنگام رسیدن به شرایط توفق ادامه می باید (Kouvelis et al,2000).
اغلب این شیوه ها در خطر همگرا شدن به یک بهینه موضعی ضعیف هستند. برای فائق آمدن به این اشکال در برخی از منابع موجود در ادبیات یک تکنیک جستجوی محلی با چندین جواب آغازین به الگوریتم اضافه شده است (Balakrishnan et al.,2003). اگر چه احتمال به دست آوردن بهینه های محلی افزایش می یابد، اما این تکنیک از لحاظ محاسباتی هزینه بر است و فقط کمی بهتر عمل می کند. تا به حال استراتژی هایی که از روش های جستجوی محلی با پذیرش جواب های همسایگی غیر بهتر استفاده کرده اند به شکل موثرتری کار کرده اند (McKendall&Shang,2006).به بیان دیگر در الگوریتم SA از ایده قبول حرکت های غیر بهبود دهنده استفاده می کند تا از به دام افتادن در بهینه های محلی ضعیف اجتناب کنند. در SA احتمال قبول حرکت غیر بهبود دهنده در ابتدا زیاد است اما هنگامی که جستجو ادامه می یابد و دما کاهش می یابد احتمال قبول حرکت غیر بهبود دهنده کاهش می یابد .(Misevicius,2006) تا به حال الگوریتم SA برای حل مسائل بهینه سازی متفاوتی در ادبیات به کار رفته است، هر چند که در تنظیم پارامترها و قدم های الگوریتم تفاوت هایی به چشم می خورد اما می توان کلیات الگوریتم را به صورت زیر بیان کرد .(McKendall et al,2006):
- انتخاب تنظیمات برای پارامترهای هیورستیک و ایجاد یک جواب اولیه و محاسبه هزینه آن (این جواب به عنوان حل جاری شناخته می شود)
- به دست آوردن حل همسایه از جواب جاری با استفاده از تکنیک های جستجوی محلی.
- به دست آوردن هزینه جواب همسایگی و مقایسه آن با هزینه حل جاری.
الف- اگر هزینه همسایه بهتر باشد به عنوان حل جاری قبول می شود.
ب- اگر هزینه همسایه بدتر باشد آنگاه با احتمالی به عنوان حل جاری قبول می شود. در غیر این صورت حل جاری را حفظ می کنیم. شمارنده و پارامترها را به روز می کنیم و قدم های ۲ تا ۴ را ادامه می دهیم، تا یک شرط توفق مناسب تحقق یابد. مهم ترین عنصر SA احتمال قبول و برنامه ریزی بازپخت می باشد. احتمال قبول به عنوان احتمال قبول یک جواب غیر بهبود یافته نسبت به جواب جاری است (Balakrishnan et al.,2003). این احتمال توسط رابطه زیر محاسبه می شود:
![]()
جایی که Tc دمای جاری است و تغییر در هزینه کل را نشان می دهد. (هزینه حل همسایه منهای هزینه حل جاری و ΔTC = f(y’) – f(y) اگر x یک عدد تصادفی در بازه ۰ و ۱ باشد و x < P(ΔTC) سپس قبول یک همسایه غیربهبود یافته به عنوان حل جاری در غیر این صورت حل غیر بهبود یافته رد می شود و حل جاری y را نگه می دارد. در آغاز احتمال قبول حل غیر بهبود یافته زیاد است و این باید هنگامی که دمای آغازی تعیین شود در نظر گرفته شود. هر چند، همانطور که دما کاهش می یابد احتمال قبول حل غیر بهبود یافته کاهش می یابد. برنامه بازپخت همچنین برنامه سردشدن را می دهد، تنظیم پارامترها برای SA، که برای کاهش دما استفاده می شود. دمای جاری با معادله زیر تعیین می شود:
Tc = T0άr-1, r = 1,2,…,R
جایی که T0 دمای آغازین است، به α نرخ سردشدن گفته می شود که معمولاً در ۱/۰ تنظیم می شود و ۱- R تعداد کاهش ها در دما است. قبل از کاهش دما تعداد تغییرات دودویی قبول شده مورد نیاز برای اجرا تا حصول اطمینان از رسیدن سیستم به حالت پایدار تعیین می شود. هنگامی که دما پایین است این امکان وجود دارد که تعداد زیادی از تغییرات دودویی اجرا شوند اما تعداد کمی از آن ها قبول می شود. بنابراین دما باید بعد از تعداد معینی از تغییرات کاهش یابد.
الگوریتم جستجوی ممنوع
اگرچه بحث جستجوی ممنوع به اواخر دهه ۱۹۶۰ و اوایل دهه ۱۹۷۰ بر می گردد ولی شکل فعلی این روش تنها چندین سال است که به طور گسترده ای مورد استفاده قرار گرفته شده است. در حال حاضر این روش به عنوان یک روش بهینه سازی که به سرعت در بسیاری از زمینه های جدید به کارگرفته می شود مطرح است. این روش به عنوان یک روش نوید بخش برای حل مسائل و کاربردهای علمی معرفی شده است. TS را می توان به عنوان تکنیکی برگرفته از مفاهیم هوش مصنوعی در نظر گرفت. این تکنیک روشی کلی برای هدایت جستجو در دست یابی به جواب های خوب در فضای جواب پیچیده است.
این روش به صورت یک الگوریتم متوالی مجموعه ای از جواب های مسئله یعنی X را با حرکت های پی در پی از یک جواب s به جواب دیگر مثل s’ در همسایگی آن، یعنی N(s) به دست می آورد. این حرکت ها با هدف رسیدن به یک جواب خوب (بهینه یا نزدیک به بهینه) و با ارزیابی تابع هدفی مثل f(s) که می بایست حداقل شود صورت می گیرند. TS را می توان به صورت یک روش ساده کاهنده به شکل زیر خلاصه کرد:
قدم ۱- یک جواب اولیه s را انتخاب کرده، فرض کنید s*=s متغیر شمارنده تکرارها (k) را مساوی صفر قرار دهید و با T تهی آغاز کنید (T لیست ممنوع است).
قدم ۲- یک لیست کاندید V از جواب های موجود در N(s) – T ایجاد کنید. اگر N(s) – T تهی است به قدم ۴ رفته در غیر این صورت قرار دهید k=k+1 و s’ V را به گونه ای انتخاب کنید که به ازای هر s” V داشته باشیم f(s’)≤f(s”).
قدم ۳- اگر f(s’)<f(s*) (s* بهترین جوابی است که تا حال به دست آمده است) قرار دهید s*=s’،
قدم ۴- اگر تکرارها به حداکثر تعداد از قبل تعیین شده رسیده و یا اگر N(s) – T=Φ است، و یا اینکه مستقیما از قدم ۲ به این مرحله رسیده اید توقف کنید. در غیر این صورت لیست T را به روز کرده به قدم ۲ برگردید.
بازدیدها: 501












