فهرست مطالب
مقدمه
همان طور که در بخش دوم مجموعه مقالات مسئله مکانیابی تسهیلات صف بندی شده مطرح شد دو مدل عمومی در ادبیات مکانیابی وجود دارد که عبارتند از
- مدل های پوشش
- مدل های میانه
مدلهای پوشش به صورت مبسوط در بخش سوم مجموعه مقالات مسئله مکانیابی تسهیلات صف بندی شده مورد بحث قرار گرفت. در ادامه در این مقاله مسئله QFLP با در نظر گرفتن تابع هدف میانه مورد بحث قرار خواهد گرفت. شایان ذکر است هدف اصلی در مدلهایی که در این مقاله مورد بررسی قرار گرفتهاند مینیم کردن متوسط زمان پاسخ در سیستم است. منظور از زمان پاسخ عبارت است از مدت زمان رسیدن تماس برای فراخوانی خدمت تا شروع خدمت.
ویژگی اصلی مدل های میانه در مسئله مکانیابی تسهیلات صف بندی شده
تقریبا می توان گفت تمام مدل های موجود در این زمینه بر اساس سرورهای سیار بنا شده و در آن ها یک دیدگاه احتمالی[۱] از مسائل میانه موجود است. بنابراین ویژگی های اصلی آن ها بدین صورت است که:
- تعداد کل مکان ها M فرض می شود
- همه مدل ها سیار می باشند.
- هر تسهیل دارای سروری است که بعد از انجام هر سرویس حتما باید به تسهیل خود بازگردد.
- در این مدل ها از عامل صفر و یک برای نشان دادن اینکه آیا یک تسهیل در مکان j مستقر شده است یا نه استفاده می شود.
- پارامتر kj برای نشان دادن تعداد سرورهای موجود در هر تسهیل استفاده خواهیم کرد به طوری که اگر xj=0 آنگاه kj=0 بوده و اگر xj=1 آنگاه kj>0 باشد.
مکانیزم اعزام خدمت دهنده و اجزای زمان خدمت دهی
هنگامی که یک درخواست برای خدمت رخ می دهد نزدیک ترین سرور با فرض اینکه حداقل یکی از آن ها آزاد باشد، اعزام می شود. توجه کنید که فرض می شود تمام مکان ها پوشش داده شده است و هیچ استاندارد پوششی وجود ندارد. زمان سرویس دارای اجزای زیر است:
- سفر به مکان خدمت رسانی از تسهیل خود.
- فراهم کردن خدمت درمکان خدمت رسانی.
- برگشت به تسهیل خود.
- احتمال عدم سرویس رسانی[۲].
بنابراین میانگین زمان یک واحد خدمت در مکان j برابر است با:
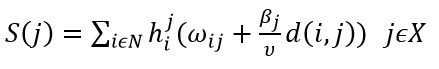
تشریح بیشتر تابع میانگین زمان یک واحد خدمت
در این معادله ijω جمع میانگین زمان های انجام خدمت رسانی و عدم انجام خدمت رسانی در محل خدمت است. j>1β ثابتی است برای نشان دادن اینکه سرعت سفر برای خدمت رسانی متفاوت است. در (Berman&Krass,2002) آمده است چنانچه سرعت ها مشابه باشد j=2β در نظر گرفته شود. پارامتر v بیانگر متوسط سرعت سفر می باشد. hij احتمال این است که یک سرور از تسهیل j برای خدمت رسانی به محل i اعزام شود که با PDij متفاوت است. لازم به ذکر است سیستم صف در این مدل ها بر اساس FCFS کار می کند. همچنین پارامتر ۰≤c نشان دهنده طول صف می باشد و حالت c=∞ هم بررسی خواهد شد. تماس هایی که بعد از پر شدن طول c برقرار می شوند مورد پذیرش قرار نمی گیرند و جریمه RC>0 برای سیستم در نظر گرفته می شود.
مدل عمومی مسئله
اما مدل عمومی که در این بخش قابل ذکر است و بقیه مدل ها از آن نشات گرفته شد به صورت زیر می باشد:
مدل عمومی مسئله QFLP
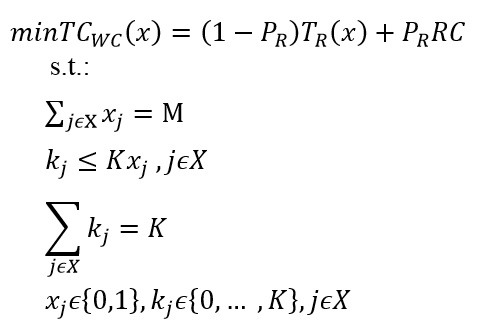
تشریح بیشتر مدل عمومی
در این مدل TR نشاندهنده زمان پاسخ انتظاری برای تماسی است که پذیرفته شده است و شامل TW زمان انتظار در صف و t زمان سفر برای خدمت می باشد. بنابراین:
TR(x)=TW(x)+t(x)
همچنین PR احتمال این است که یک تماس تصادفی توسط سیستم پذیرفته نشود. در واقع تابع هدف جمع میانگین زمان پاسخ و هزینه نپذیرفتن مشتری را کمینه می کند. در ضمن K هم نشاندهنده ماکزیمم سرورهای موجود در سیستم است.
فرض حالت نمایی برای کل زمان سرویس دهی
همچنین اگر ما فرض کنیم که کل زمان سرویس دهی (شامل زمان های رفت و برگشت و سرویس دهی و عدم سرویس دهی) نمایی باشد، سیستم صف M/M/K/c با سرورهای متمایز به دست می آید. Larson در سال ۱۹۷۴ از احتمالات در حالت پیوسته برای چنین سیستمی استفاده کرد و راه حلی برای سیستمی بزرگ با این معادلات به دست آورد، در واقع کار او پایه گذار مدل فوق مکعبی بود. اما فرض نمایی بودن کل زمان سرویس غیر واقعی است. البته زمان سرویس دهی و عدم سرویس دهی نمایی است اما زمان سفر به مکان مشتری اغلب نمایی نیست بنابراین کل زمان سرویس دهی ممکن است نمایی نباشد.
توسعه مدل عمومی
اما مدل های این قسمت را به چند دسته بر اساس یک تسهیله یا چند تسهیله و بر اساس همکاری و یا عدم همکاری سرورها با هم تقسیم کرده ایم.
حالت یک تسهیل: مسائل احتمالی میانه زیان و میانه صف
در این قسمت قصد داریم حالت تک تسهیلی را که تحت عنوان مسائل احتمالی میانه زیان[۳] و میانه صف[۴] شناخته می شوند را مرور کنیم. ابتدا در این قسمت با حالت یک سرور آغاز می کنیم. به عبارت دیگر M و K برابر ۱ است. این مسئله در دو حالت c=∞ و c=0 توسط Berman و همکارانش در سال ۱۹۸۵ بررسی شده است. هنگامی که c=0 یک تماس برای سرویس ممکن است در مکان خود پذیرفته و یا رد شود. بنابراین مدل عمومی بدین شکل کاهش می یابد:
![]()
که
![]()
میانگین کسر زمانی است که سرور مشغول است و
![]()
یک حل بهینه برای این مسئله میانه احتمالی زیان در یک شبکه به نام G است. این حل به وسیله (Berman,1985) و همکارانش نشان داده شده است. اما هنگامی که c=∞ هیچ مشتری رد نمی شود و بنابراین مدل عمومی به مسئله زیر تبدیل می شود:
![]()
اگر برای این مدل یک سیستم صف M/G/1 در نظر بگیریم زمان انتظار به وسیله معادله زیر محاسبه می شود(Kleinrock,1975):
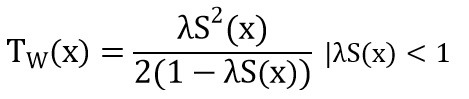
به صورتی که (S(x زمان مورد انتظار برای سرویس و (S2(x گشتاور دوم زمان سرویس باشد:
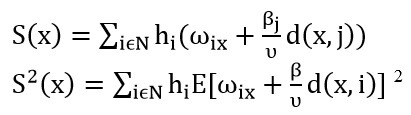
که در آن E[.] مقدار انتظاری است که از توزیع ixω داریم. جواب بهینه برای حالت c=∞ میانه صف احتمالی (SQM) نامیده می شود که توسط Berman و همکارانش در سال ۱۹۸۵ ارائه گردید. ناگفته نماند که این مدل در حالت یک تسهیله دوباره توسط Berman در سال ۱۹۹۰ گسترش داده شد.Chiu و Larsonدر سال ۱۹۸۵ این مسئله را برای حالت M/G/K/0 گسترش دادند که در آن PR بر اساس تابع زیان ارلنگ برابر عبارت زیر است:
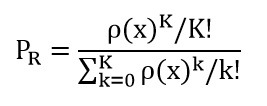
Batta و Berman در سال ۱۹۸۹ تخمین مناسبی برای (TW(x بر اساس منبع (Nozaki& Ross,1978) ارائه دادند که برابر عبارت زیر است:
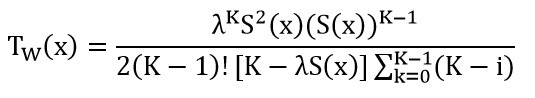
که البته Batta و Berman در سال ۱۹۸۹ برای ارزیابی و اعتبارسنجی این عبارت شبیه سازی آن را پیشنهاد داده اند.
حالت چند تسهیل: یک سرور در هر تسهیل و بدون همکاری سرورها
در این بخش مباحث مطرح شده در قسمت قبل را برای حالت چند تسهیلی با فرض این که سرورها یکدیگر را کمک نمی کنند، گسترش داده می شود.
فرض عدم وجود همکاری بین تسهیلات
در مدل عمومی تسهیلات به طور ضمنی با هم همکاری می کردند. این همکاری بدین صورت بنا شده بود که نزدیک ترین سرویس همیشه برای خدمت رسانی اعزام می گردید. بنابراین هنگامی که همه سرورهای یک تسهیل مشغول بودند و یک فراخوانی سرویس برای این تسهیل رخ می داد، سروری از تسهیل دیگری برای خدمت دهی اعزام می شد. در این بخش فرض می کنیم که هیچ همکاری بین تسهیلات وجود ندارد و مشتری باید تا آزادشدن سرورهای تسهیل مورد نظر صبر کند. فرض عدم همکاری تسهیلات شبیه فرض های ناحیه ای است که قبلا مورد بحث و بررسی قرار گرفت.
ایجاد مدل M-median
تحت این فرضیات با مسئله ای مواجه هستیم که در آن می خواهیم به طور همزمان قلمرو سرویس دهی را با بخش بندی گره های تقاضای مشتریان به ناحیه ای که یک تسهیل سرویس رسانی کند، تعیین کنیم و مکان مناسبی برای تسهیل در هر ناحیه پیدا کنیم و کل زمان پاسخ در شبکه را کمینه کنیم؛ هنگامی که c=0 است. در واقع در هر ناحیه دارای یک مسئله SLM یا ۱-median هستیم. حال اگر دارای چند ناحیه باشیم کل مسئله به مسئله M-median تبدیل می شود. اما برای حالت c=∞ حتی اگر فرض کنیم که تسهیلات چیده شده اند، پیدا کردن ناحیه های هر تسهیل به خودی خود بسیار پیچیده است.
Berman و Larson در سال ۱۹۸۵ ناحیه بندی شبکه ای با ۲ تسهیل را بررسی کرده اند. آن ها این کار را با گروه بندی نرخ تماس ها λ انجام دادند که به دلیل پیچیدگی بیش از حد در این بخش آورده نمی شود. اما برای مرور جزئیات آن می توان به (Berman&Larson,1985) و (Berman& Krass,2002) رجوع کرد. Berman و Larson در سال ۱۹۸۵ بیان کرده اند که برای چنین مدل پیچیده ای به هیچ وجه راه حل های دقیق کاربردی نداشته و برای حل آن استفاده ابتکاریی که از روش های ترکیب محدب[۵] (Wagner,1975) پیشنهاد شده است. همچنین Berman و Mandowsky در سال ۱۹۸۶ موفق شدند با استفاده از روش های ابتکاری مکان و ناحیه بندی بهینه این مسئله را پیدا کنند.
حالت چند تسهیل: یک سرور در هر تسهیل و با در نظر گرفتن همکاری سرورها
در این قسمت مسئله QFLP را در حالتی که در هر تسهیل یک سرور مستقر است و ظرفیت صف باشد و همچنین بین تسهیلات همکاری و مشارکت بر قرار باشد بررسی خواهیم کرد. چنین مسئله ای توسط Berman و همکارانش در سال ۱۹۸۷ بررسی شده است. کلید چنین سیستمی بر اساس مدل فوق مکعبی (Larson,1974) و بر اساس تخمین M/M/1 این سیستم با سرورهای متمایز انجام شد که اجازه محاسبه نسبت تقاضای هر مشتری و بکار بردن آن برای هر تسهیل خاص را می داد. ایشان برای حل این مسئله یک روش ابتکاری ارائه نموده اند. این روش گام به گام گره ها را بررسی می کند تا بهبودی در تابع هدف رخ دهد. آن ها همچنین روش ابتکاری دیگری را برای سیستم صف M/G/1 در حالت چند تسهیل ارائه نمودند.
تعداد عمومی تسهیلات با در نظر گرفتن سفرهای بدون بازگشت سرورها به تسهیل[۶]
در بخش های قبل فرض بر این بود که هر سرور بعد از خدمت رسانی برای خدمت رسانی بعدی باید به تسهیل خود بازگردد. همان طورکه مشخص است این فرض از بسیاری جهات با دنیای واقعی تطابق ندارد، به عنوان مثال پلیس بعد از انجام خدمت خود لزوما به پایگاه خود باز نمی گردد یا به طور مثال در مورد سرویس های آتش نشانی این مطلب صدق نمی کند. البته برای سرورهای غیر اورژانسی مثل سرورهای خدمات پس از فروش هم فرض بازگشت به تسهیل صدق نمی کند.
چنین مسئله ای توسط Berman و Vasudeva در سال ۲۰۰۰ برای حالت بررسی شد. قابل ذکر است در صورتی که سرور پس از انجام هر خدمت تماسی برای سرویس دهی نداشته باشد باید به تسهیل خود بازگردد. مدل سازی چنین مسئله ای حتی در حالت تک تسهیلی و تک سروری هم بسیار مشکل است (Berman&Vasudeva,2000). ایشان برای این دوره های زمانی مختلفی را در نظر گرفتند و سرویس های پشت سر هم بدون بازگشت به تسهیل در پریود های شلوغ رخ می دهد. در این مقاله سیستم صف M/G/1 مورد استفاده قرار گرفته و برای تشکیل پارامتر (TW(x از نتایج تحقیقات (Odoni,1969) بهره گرفته شده است.
جمع بندی و معرفی زمینه های تحقیقاتی
در این مجموعه مقالات سعی بر آن بود تا یک دیدگاه کلی و جامع از مسائل مکانیابی تسهیلات صف بندی شده را ارائه نماییم. نتایج بررسی های نشان داد علی رغم گستردگی ادبیات QFLP هنوز زمینه های زیادی برای تحقیق و بررسی در مورد آن ها وجود دارد. کافیست به این مسئله اشاره شود که هیچ کدام از مدل های بررسی شده تلاشی برای به وجود آوردن مدلی با تمام ویژگی های تعیین شده که در مدل عمومی بیان شده، نکرده اند. مدل های بیان شده در قسمت پوشش گرایش زیادی به ایجاد فرضیات ساده ساز در مدل های خود دارند و در عین حال در بسیاری از حالات قوانین اعزام سرورها، درجه همکاری سرورها و غیره که تاثیر زیادی بروی مسئله دارند نادیده گرفته می شود.
باید به این نکته اشاره کرد که با وجود محدودیت استاندارد سازی پوشش هنوز هم این سوال در این مدل ها وجود دارد که آیا پوشش کافی ایجاد می شود؟ و باید گفت چنین سوال هایی در حالات عملی و کاربردی تنها با شبیه سازی به طور دقیق پاسخ داده می شود. البته این کارها بیشتر برای مقایسه شکل های مختلف QFLP مناسب می باشد. همان طور که گفته شد بسیاری از فرضیات در مدل های قسمت Covering واقعی نیستند اما با این وجود بدون این فرضیات پیش بینی حوزه مدل ها دشوار است. بنابراین احساس می شود پیشنهادات بسیاری برای طراحی کاربردی تر این مدل ها می توان ارائه کرد.
اما در مدل های بیان شده در قسمت Median تئوری صف به صورت جامع تر و کاربردی تر استفاده شده است که البته نتیجه آن مشکل تر شدن نتیجه گیری در این مدل ها و حل بسیار پیچیده آن هاست، به طوریکه در اغلب مدل های این قسمت تنها راه حل های ابتکاری جوابگوست. به علاوه ضمانت پوشش در این مدل ها وجود ندارد. هر چند که فرضیات غیرواقعی در این مدل ها کمتر دیده می شود. ضمنا در مدل های قسمت Median تنها بروی سرورهای سیار کار شده است و به همین دلیل تقسیم بندی گزارش در این قسمت با قسمت Covering متفاوت است. اما باید گفت مدل های قسمت Median در مورد فرضیات و ویژگی های سرورها به طور دقیق تر صحبت کرده اند. لازم است دوباره به این مطلب اشاره کرد که برای آزمایش عملکرد نتایج مدل ها در این قسمت نیز باید با شبیه سازی سیستم مدل شده به مقایسه نتایج پرداخت.
اما در مورد پیشنهادات بیشتر برای تحقیقات آینده بهترین موضوع کار بروی مدل های غیر اورژانس و با تسهیلاتی با سرورهای ثابت است. درست است که کار بروی این مدل ها ساده تر به نظر می رسد و کاربرد تئوری صف در آن ها بیشتر است اما تطبیق آن ها با دنیای واقعی بسیار با اهمیت می باشد مانند سیستم بازار خرده فروش ها در یک زنجیره تامین. البته کار بروی روش های حل ساده تر و سریع تر همیشه در این زمینه به عنوان پیشنهاد برای تحقیقات آتی وجود دارد.
پاورقی ها
بازدیدها: 150