
فهرست مطالب
مقدمه
در این مقاله مسئله QFLP با در نظر گرفتن مسائل پوشش را مورد بحث قرار داده و بحث پیرامون مسئله QFLP با در نظر گرفتن تابع هدف میانه را به مقاله آتی موکول می نماییم. لازم به ذکر است همان طور که در بخش دوم مجموعه مقالات مسئله مکانیابی تسهیلات صف بندی شده مطرح شد مسائل پوشش به دو نوع پوشش مجموعه و ماکزیمم پوشش وزنی تقسیم می شوند. محققان عزیز می توانند برای مطالعه بیشتر این دو کلاس از مسائل پوشش به (Berman&Krass, 2002) و مقالات «مکانیابی تسهیلات و مدیریت زنجیره تامین» و «مسئله طراحی و چیدمان تسهیلات» مراجعه نمایند.
تفاوت های بین مدل های مسائل پوشش
تفاوت در ماهیت خدمت دهندگان (سیار یا ثابت)
مدل سازی مسائل پوشش کاملاً مشابه یکدیگر است. برگردان این مدل ها و رویکردهای حل آن ها در حالت احتمالی و QFLP هم بسیار به هم نزدیک می باشند. اما تفاوت اساسی که بین مدل ها می تواند وجود داشته باشد و در مقاله قبل بیان شد، تفاوت ماهیت سرورهاست که سیار یا ثابت هستند. در مسائل پوشش پارامتر Ni تعریف می شود که مجموعه مکان های قرارگیری تسهیل با ماکزیمم فاصله تعیین شده از i می باشد. در حالت سرورهای سیار تخصیص سرورها به مشتریان به شرایطی بستگی دارد که آیا سروری در دسترس می باشد یا خیر در صورتی که در حالت سرور ثابت، مشتری خود به انتخاب سرور اقدام می کند. بنابراین مسئله پوشش در دو حالت سرور ثابت یا سیار بیان می شود که در ادامه بیان می شود.
مکانیزم احتمالی استفاده شده (تراکم صریح یا ضمنی)
تفاوت دیگری که در مسائل QFLP با در نظر گرفتن مسائل پوشش مطرح است مکانیزم احتمالی استفاده شده در بیان تراکم در سیستم است که به دو نوع تراکم صریح و تراکم ضمنی تقسیم می شود. حالت صریح مبتنی بر تکنیک های صف می باشد اما حالت ضمنی با استفاده از تخمین پارامترهایی مانند نرخ استفاده از سرورها، سعی در نشان دادن تراکم در سیستم را دارد، هرچند که تعیین حدود بین این دو نوع تراکم تا اندازه ای مبهم است و رویکرد های ضمنی به سمت توصیفات صریح نزدیک شده اند.
مسئله مکانیابی تسهیلات صف بندی شده با در نظر گرفتن مسائل پوشش و سرورهای سیار (تخصیص پویای سرور)
در این قسمت مدل هایی که بر اساس پوشش طراحی شده و دارای سرورهای سیار هستند (تخصیص پویای سرور[۱]) را مورد بررسی قرار می دهیم. همه مدل های بررسی شده در این قسمت معیاری مشابه در پوشش را بکار می گیرند. این معیار عبارت است از احتمال اینکه یک درخواست برای گرفتن سرویس، سروری آزاد و در دسترس یافت کند باید به اندازه کافی زیاد باشد. بیشتر مدل های مربوط به این قسمت دنباله رو مدل مسئله مکانیابی حداکثر پوشش انتظاری[۲] (MEXCLP) که در سال ۱۹۸۳ توسط Daskin توسعه یافت، هستند.
فرض کنید که برای مشتری در مکان i، درخواست برای سرویس فقط توسط واحدهایی صورت پذیرد که که دارای ماکزیمم فاصله مشخص از مکان i هستند. بدین صورت که در محدودیت مربوطه، Ni مکان های دارای پتانسل قرارگیری تسهیل که فاصله مورد نیاز i را برطرف می کنند، می باشند. Daskin در سال ۱۹۸۳ برای بررسی احتمال اینکه یک سرور در هنگام اینکه فراخوانی برای سرویس رخ می دهد در دسترس نباشد، از سه فرض ساده ساز استفاده کرد:
- سرورها از هم به صورت مستقل عمل می کنند، بنابراین احتمال اینکه سرور j مشغول باشد مستقل است از اینکه سرور k مشغول باشد j≠k،
- احتمال مشغول بودن سرورها با هم برابر است،
- احتمال مشغول بودن سرورها نسبت به مکان سرور و حجم کاری آن ها تغییر نمی کند.
این فرض ها به این مطلب اشاره می کنند که احتمال مشغول یافتن یک سرور خاص در هر زمانی برابر p است که به صورت یک پارامتر خارجی در مدل رفتار می کند.
فرض کنید که تعداد سرورهای قرار گرفته در Ni برابر k باشد. تعداد سرورهای مشغول می تواند توسط توزیع برنولی مدل شود. بنابراین احتمال اینکه یک فراخوانی برای سرویس، یک سرور آزاد را پیدا کند برابر ۱-pk است. حال فرض کنید تعداد سرور ها به k+1 افزایش یابد بنابراین احتمال اینکه یک سرور آزاد یافت شود به (rk+1=pk(1-p افزایش می یابد.
در صورتی که مشتری i توسط k سرور پوشش داده شود، مقدار متغیر تصمیم yik یک خواهد بود و در غیر اینصورت مقدار صفر را به خود خواهد گرفت. بنابراین احتمال اینکه فراخوانی سرویس i یک سرور آزاد وجود داشته باشد برابر α است. حال اگر مقدار زیر را به عنوان کران پایین تعداد تماس های مورد انتظار برای هر مکان پوشش داده شده در نظر بگیریم، محدودیت سطح سرویس به صورت زیر بیان می شود.
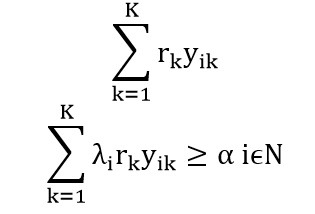
قابل ذکر است iλ نرخ برقراری تماس ها از محل مشتری i می باشد. همچنین LCjk هزینه استقرار k سرور در مکان j می باشد. فرض کنید این هزینه متناسب باشد با تعداد k سرور موجود پس
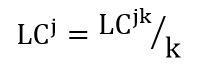
بنابراین در حالت پوشش مجموعه داریم:
Model A:
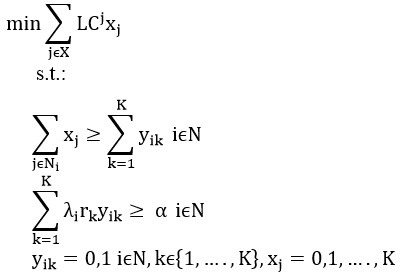
قابل ذکر است xj متغیر تصمیمی است که نشاندهنده تعداد سرورهای قرار گرفته در مکان j می باشد و K ماکزیمم تعداد سرورهایی است که می تواند مستقر شود. همچنین می توان کل تعداد سرورهای مستقر شده را ثابت K در نظر گرفت و در تابع هدف تعداد تماس های مورد پوشش انتظاری را ماکزیمم کرد ( مدل حداکثر پوشش وزنی) پس:
Model B:
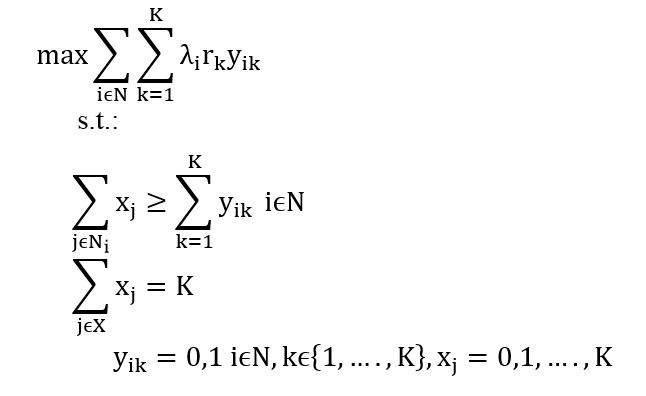
البته قابل ذکر است Daskin در سال ۱۹۸۳ مدل دوم را پیشنهاد داد و یک حل ابتکاری که بر اساس جابجایی گره است، ارائه کرد. قابل توجه است که مدل های A و B از نوع برنامه ریزی عدد صحیح است. همان طور که مشاهده می شود پارامتر احتمال یافتن یک سرور آزاد به عنوان یک عامل خارجی در سیستم و مدل عمل می کند. بنابراین می توان گفت MEXCLP یک مدل QFLP واقعی نیست، زیرا عامل تراکم به خوبی در آن شکل نگرفته است.
Batta و همکارانش در سال ۱۹۸۹ تلاش کردند تا فرضیات مستقل بودن سرورها از هم را کاهش دهند. البته قبل از آن Larson در سال ۱۹۷۵ فرض احتمال مشغول بودن سرورها را بر اساس تنظیماتی در تابع هدف کاهش داد. بدین صورت که با ضرب عامل (Q(K,p,k-1 در هر عبارت (rk=pk-1(1-p تلاش بر وابستگی بین سرورها شده است. ایده اصلی بدین صورت است که اگر مکان i بوسیله k سرور پوشش داده شود، به منظور اینکه kامین تماس در مکان i پاسخ داده شود، k-1 سرور دیگر حتما باید در نقاط دیگر مشغول باشند. فرض کنید که برای هر تماس سرورها به صورت تصادفی انتخاب شوند بنابراین عامل تصحیح (Q(K,p,k-1 برابر عبارت زیر می باشد.
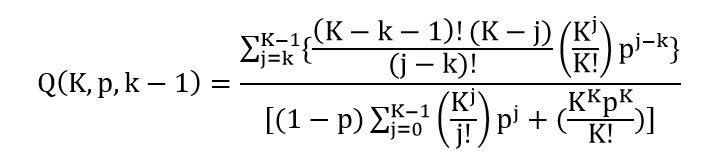
که در این عبارت k=0 ,… ,K-1 می باشد.
بنابراین تابع هدف مدل MEXCLP بدین صورت تغییر می کند:
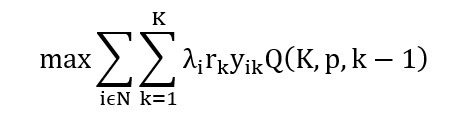
بر اساس تحقیقات Batta و همکارانش در سال ۱۹۸۹ نتیجه بهینه گرفته شده از تابع هدف مدل جدید هنگامی که احتمال مشغول بودن سرور بالای ۰٫۵ است، تغییر چشمگیری می کند. البته Batta در همان سال مدل دیگری برای مسئله QFLP که در نتیجه توسعه مدل فوق مکعبی[۳] Larson در سال ۱۹۷۴ به دست آمده، بیان کرده اند که در بخش های بعد به آن خواهیم پرداخت.
اما Revelle و Hogan در سال ۱۹۸۹ رویکرد دیگری را برای مدل MEXCLP در نظر گرفتند و آن را MALP [4] نامیدند، بدین صورت که پارامتر p را با تخمینی از pi جایگزین کردند که در واقع برای هر محل از مشتری ها متفاوت است. این تخمین مبتنی بر دو فرض است که در دیگر مدل های QFLP نیز کم و بیش دیده می شود. همان طور که گفته شد Ni𝜖X نشاندهنده مکان هایی است که پتانسیل قرارگیری تسهیل را دارند و دارای ماکزیمم فاصله معین در حوزه i می باشند. همچنین فرض کنید که Mi𝜖N مجموعه دیگر مکان های مشتریان است که در فاصله ماکزیمم از i قرار دارند (Ni𝜖Mi و N=X). پس داریم:
- همه فراخوانی ها برای سرویس تولید شده از مکان هایی در Ni به وسیله تسهیلاتی در Mi سرویس می گیرند.
- تسهیلات موجود در Mi فقط فراخوانی سرویس تولید شده از Ni را پاسخ می دهند.
به فرضیات بیان شده فرضیات ناحیه ای[۵] می گویند. فرضیات ناحیه ای چندان در واقعیت صدق نمی کنند اما مسئله را بسیار ساده می سازد. اگر pi برابر احتمال این باشد که یک سرور در Ni مشغول باشد، یک تخمین خوب برای آن iρ است که نشان دهنده نرخ استفاده سرورها در Ni تقسیم بر تعداد سرورها در Ni می باشد. بنابراین
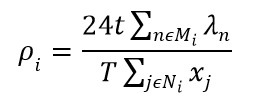
T در اینجا کل زمان هایی است که سرور در دسترس است و معمولا T=24 است. قابل ذکر است Chapman و Whiteدر سال ۱۹۷۴ سعی در خطی سازی محدودیت سطح سرویس دهی داشتند که به موفقیت هایی هم منجر شد که در (Berman&Krass,2002) به تفصیل آمده است. مدل MALP به صورت زیر نشان داده می شود:
Model C:

در این مدل
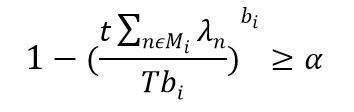
همه مدل های توصیف شده در بالا دارای مفهوم ضمنی تراکم هستند زیرا تکیه آن ها بر توزیع دوجمله ای است و از این حقیقت که بعضی از سرورها ممکن است نسبت به بعضی دیگر کمتر در دسترس باشند، چشم پوشی می کنند. برای این منظور Marianov و Revalle در سال ۱۹۹۶ مفهومی مبتنی بر تئوری صف بروی مدل MALP گذاشتند. همچنین آن ها برای فرضیات ناحیه ای از فرمی معادل آن استفاده کردند که بدین صورت بیان می شود:
برای هر همسایه مجموعه Mi تعداد فراخوانی های سرویس تولید شده خارج از Mi تقریباً برابر تعداد تماس های تولید شده درMi است و به وسیله سرورهای خارج Ni خدمت رسانی می شوند. بنابراین هر کدام از همسایه های Mi در صفی جداگانه از سیستم رفتار می کنند. دومین فرض مهمی که Marianov و Revalle بروی مدل خود نهادند این است که زمان سفر سرورها به محل مشتری بسیار کوچکتر از زمان سرویس دهی است و می تواند مورد چشم پوشی قرار بگیرد. همچنین فرض شد که زمان سرویس دهی دارای توزیع نمایی است. بنابراین سیستم با صف M/M/k عمل می کند و احتمال اینکه همه سرورها مشغول باشند برابر رابطه زیر است.
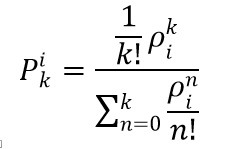
که در اینجا
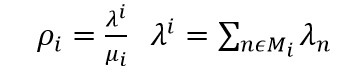
در ضمن اگر بخواهیم اطمینانی از وجود حداقل bi در Ni داشت می توان بیان کرد:
![]()
Marianov و Revalleدر سال ۱۹۹۶ مدل خود را به صورت Q-MALP[6] معرفی نمودند. البته آن ها نسخه پوشش مجموعه همین مدل را در سال ۱۹۹۴ تحت عنوان Q-LSCP[7] معرفی کرده بودند. اما مشکلی که در مدل Q-MALP وجود دارد این است که انحراف bi از این حقیقت که همه مشتریان در Mi ممکن است پوشش داده نشوند، چشم پوشی می کند و بنابراین تخمین بالایی[۸] از نرخ تعداد تماس های ورودی در Mi وجود دارد.
از دیگر مدل هایی که در این قسمت وجود دارد مدل ارائه شده در Ball و Lin در سال ۱۹۹۳ می باشد.
مسئله مکانیابی تسهیلات صف بندی شده با در نظر گرفتن مسائل پوشش و سرورهای ثابت (تخصیص ایستای سرور )
در این بخش به بررسی مدل های به وجود آمده بر اساس تخصیص ایستای سرورها[۹] به مشتریان خواهیم پرداخت که در واقع معادل حالتی است که سرورها به صورت ثابت در تسهیل خود مستقر شده اند (مانند بیمارستان یا بانک). ممکن است تخصیص مشتریان به تسهیل توسط انتخاب های قانونمند از طرف مدیریت و یا از طرف خود مشتری باشد. البته معمولا یک سری قوانین در این مدل ها به چشم می خورد مانند اینکه مشتری همیشه از نزدیک ترین تسهیل سرویس می گیرد. دو مدل اساسی در این زمینه به وسیله Marianov و Serra در سال ۱۹۹۸ طراحی شده اند. این مدل ها از شکل حداکثر پوشش وزنی آغاز شدند، بدین صورت که M تسهیل ثابت برای ماکزیمم کردن پوشش به مشتریان تخصیص داده می شود. پوشش یک مشتری بدین صورت مورد بررسی قرار می گیرد که:
۱- مشتری تا یک فاصله زمانی یا فاصله ای مشخص و استاندارد به تسهیل اختصاص می یابد.
۲- احتمال اینکه مشتری با بیشترین زمان انتظار برای استفاده از محل خود وارد صف شود حداقل α باشد یا احتمال اینکه مشتری به محض ورود به تسهیل سرویس دریافت نماید برابر α با شد باشد.
مدل سازی این مسئله بر اساس متغیرهای صفر و یک صورت گرفته است، بدین صورت که xj=1 اگر تسهیلی در مکان j گشایش یابد و ۰ در غیر این صورت. همچنین yij=1 در صورتی که مشتری در i به تسهیل موجود در j اختصاص یابد. بنابراین مدل سازی چنین مسئله ای به صورت زیر می شود:

محدودیت اول تضمین می کند که یک کاربر به گره ای تخصیص یابد در صورتی که تسهیلی در آن گره مستقر باشد، دومین محدودیت تضمین می کند که هر کاربر فقط به یک تسهیل تخصیص می یابد و سومین محدودیت هم تعداد مشخص تسهیلات را به تعداد M محدود می کند. مسئله پیش رو عبارت های زیر می باشد که باید به شکلی مناسب درآیند.
بر اساس استانداردسازی صف M/M/1 که در (Kleinrock,1975) موجود است و بر اساس تحقیقات (Marianov&Serra,1998) عبارت اول به شکل زیر در آمد.
![]()
که در آن فرض شده در هر تسهیل دقیقا یک سرور قرار گرفته و متوسط زمان سرویس در گره j برابر
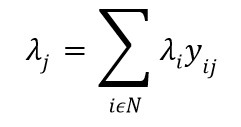
مدل دومی که توسط (Marianov&Serra,1998) بررسی شد با این فرض بنا شد که در هر تسهیل دقیقا k سرور مستقر شده باشند. در این مدل نتایج بررسی های (Kleinrock,1975) درباره سیستم صف M/M/k هم بکار گرفته شد و عبارت زیر بر اساس احتمال اینکه حداقل c+1 کاربر در صف منتظر باشند کوچکتر یا مساوی
![]()
به دست آمد.
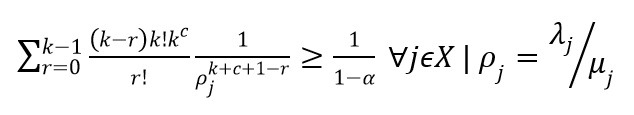
در نهایت عبارت دوم به صورت زیر نوشته می شود.
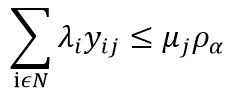
Marianov و Serra در سال ۱۹۹۸برای حل این مدل ها از روش شاخه و کران استفاده کردند، البته حل ابتکاری ساده ای هم برای آن ارائه کردند که جواب های مناسبی از این حل به دست آمد. از دیگر مدل ها در این زمینه مدل (Marianov&Rios,2000) است که برای پیدا کردن مکان های بهینه مراکز ATM در شبکه های مخابراتی بکار می رود. این مدل کمی از لحاظ مدل سازی متفاوت با مدل های بیان شده است ولی در طراحی آن از همین مفاهیم استفاده شده است. درضمن در مدل (Marianov&Rios,2000) هزینه ای با عنوان کل هزینه قرارگیری تسهیلات TCLC به تابع هدف اضافه شده است.
پاورقی ها
- [۱] Dynamic Server Assignment
- [۲] Maximum Expected Covering Location Problem
- [۳] Hypercube Queuing Model
- [۴] Maximum Availability Location Problem
- [۵] Districting Assumption
- [۶] Queuing Maximum Availability Problem
- [۷] Queuing Location Set Covering Problem
- [۸] Overstimate
- [۹] Static Server Assingment
بازدیدها: 127
مطالب زیر را حتما بخوانید
 مسئله مکانیابی تسهیلات صف بندی شده (بخش اول): معرفی
مسئله مکانیابی تسهیلات صف بندی شده (بخش اول): معرفی
 مسئله مکانیابی تسهیلات صف بندی شده (بخش دوم): مدل پایه
مسئله مکانیابی تسهیلات صف بندی شده (بخش دوم): مدل پایه
 مسئله مکانیابی-مسیریابی (بخش دوم): دسته بندی مسئله
مسئله مکانیابی-مسیریابی (بخش دوم): دسته بندی مسئله
 مکانیابی تسهیلات:دسته بندی مدل های مکانیابی تسهیلات (بخش دوم)
مکانیابی تسهیلات:دسته بندی مدل های مکانیابی تسهیلات (بخش دوم)
 مکانیابی تسهیلات رقابتی (Competitive Facility Location): مسئله تصاحب بیشینه (بخش هشتم)
مکانیابی تسهیلات رقابتی (Competitive Facility Location): مسئله تصاحب بیشینه (بخش هشتم)






